
推理大模子开卷新标的,阿里开源长文本深度念念考模子 QwenLong-L1,登上 HuggingFace 本日热点论文第二。

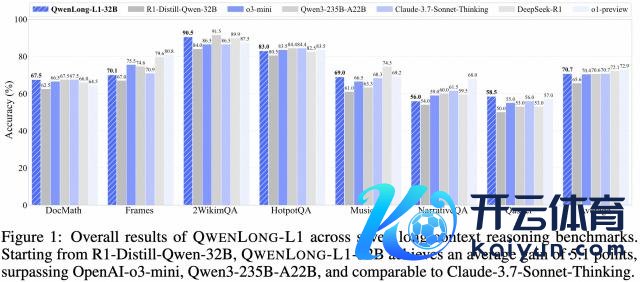
其 32B 参数版块朝上 OpenAI-o3-mini、Qwen3-235B-A22B 等,赢得与 Claude-3.7-Sonnet-Thingking 相称的性能。
除测评分数外,论文中还夺目展示了一个金融文档推理的案例。传统模子容易被无关细节误导,而 QwenLong-L1 通过回溯和考据机制过滤干与信息,正确整合谬误数据。
任务条目:字据文档讨教问题"将优先单子的刊行成本与第一年的利息支拨团结计较,总成本成本是几许?"

起初出场的基础模子 DeepSeek-R1-Distill-Qwen-14B 被文档中"自 2011 年 10 月 15 日起每半年支付一次利息"误导,字据不关联的技术和财务信息,失实计较了第一年的利息支付。

接下来,经过稀疏 SFT 的版块仍然未能惩处这个问题。
它在对不关联文档进行过度分析的轮回中自我怀疑,最终尽了最大生成为止(10000 tokens),却莫得给出最终谜底。

比较之下,诚然 QwenLong-L1-14B 起初也推崇出雷同的分神,但它很快进行了灵验的自我反念念。通过实时考据和回溯,顺利过滤掉了不关联的细节,得出了正确谜底。

那么,QwenLong-L1 是怎么作念到的?
起初,现存推理模子在靠近长文本(如几万字以致更长)时遭遇什么问题?
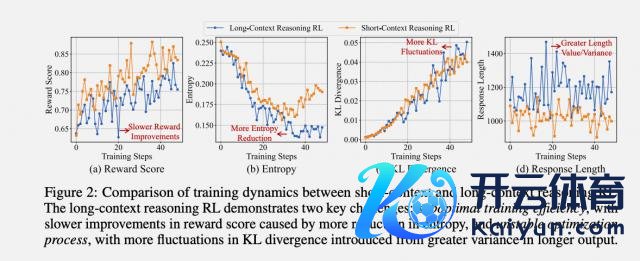
Qwen 团队通过对比执行发现,长文本推理的强化学习教练存在两个"硬伤":
一是教练效用低,传统强化学习(RL)关节在长文本中容易堕入局部最优,奖励管束慢,为止了战略优化时的探索行动。
二是优化经由对抗稳,长文本任务的输出长度更高、输入长度散播不均匀,导致战略更新时的方差被放大,教练经由中参数更新对抗稳(如 KL 散度坐过山车)。
为此团队提议 QwenLong-L1 教练框架,中枢是通过渐进式高下文推广让模子慢慢合适长文本推理。教练经由分为两阶段:
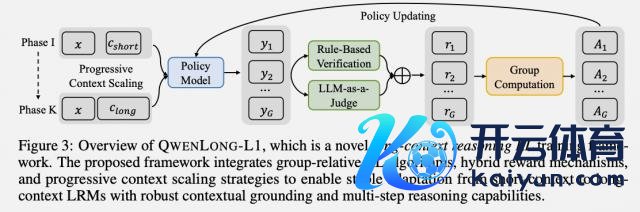
预热监督微调(Warm-Up Supervised Fine-Tuning)
在初始强化学习之前,先用高质地的演示数据进行监督微调,让模子先具备基本的长文身手路身手、推理链生成身手和谜底索取身手。
团队从 DeepSeek-R1 蒸馏了 5.3K 个高质地的问题 - 文档 - 谜底三元组,确保模子有个舒适的滥觞。执行收尾明白,这个"热身"阶段对后续的强化学习教练至关逶迤。

课程率领的分阶段强化学习(Curriculum-Guided Phased Reinforcement Learning)。
从漫笔本慢慢过渡到长文本。举例,先教练模子处理 2 万 token 的文本,舒适后再增多到 6 万 token,临了到 128K。每个阶段只矜恤对应长度的文本。
此外还引入了难度感知的回溯采样机制。在参加下一阶段时,会保留前一阶段中最难的样本(平均准确率为零的那些),确保模子不会"健忘"怎么处理困难案例。

长文本问答的谜底陆续比较绽开,单纯的功令匹配太拘泥,可能漏掉正确谜底。
QwenLong-L1 在强化学习教练中领受混杂奖励函数,结合了基于功令的考据和 LLM-as-a-Judge。

功令考据也即是平直检查谜底是否与次序谜底统长入致(如数学题计较收尾是否正确),再用另一个模子判断谜底的语义是否正确(支吾谜底表述不同但道理一致的情况),两者结合幸免单一功令过于严格或宽松

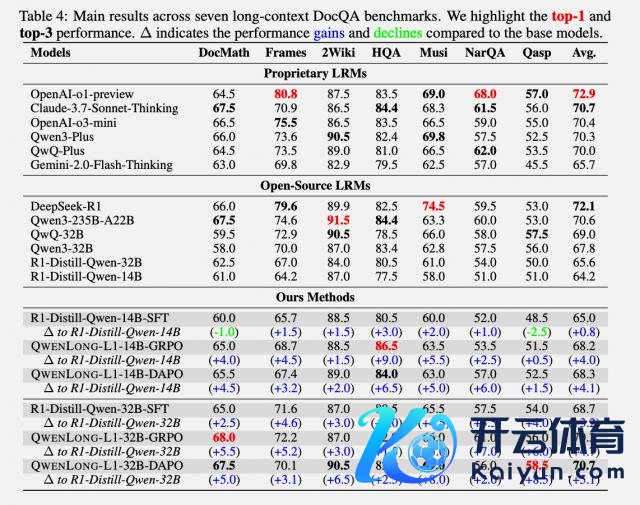
在 DocMath、Frames、2WikimQA 等七个长文本基准测试中,QwenLong-L1-14B 比较基础模子 R1-Distill-Qwen-14B,平均进步了 4.1 分,卓著了 Gemini-2.0-Flash-Thinking 和 Qwen3-32B。
QwenLong-L1 的 32B 版块比较基础模子进步了 5.1 分,达到 70.7 的对等分。这个收货不仅朝上了 OpenAI-o3-mini(70.4 分)、Qwen3-235B-A22B(70.6 分),以致和 Claude-3.7-Sonnet-Thinking(70.7 分)打成平手。
团队还针对 Test-time Scaling 性能作念了评估。当生成 16 个候选谜底时,QwenLong-L1-14B 的推崇朝上了 DeepSeek-R1 和 OpenAI-o1-preview。
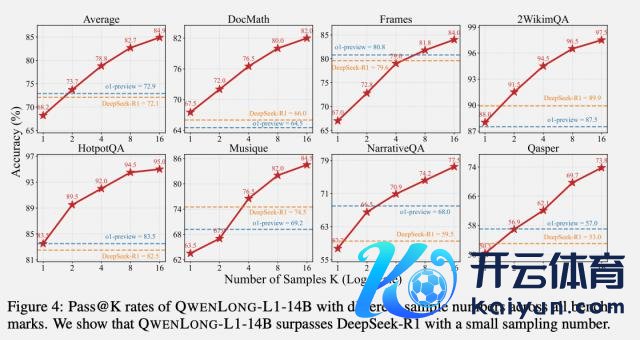
临了论文中还长远斟酌了两个问题:
既然 SFT 相对浅显低廉,为什么还要良友搞强化学习(RL)?
执行收尾很有启发性。长文本 SFT 如实能带来 2.6 分的进步,比漫笔本 SFT 的恶果更好。然而,若是在长文本 SFT 的基础上再作念 RL,进步幅度唯有 0.3 分;而在漫笔本 SFT 基础上作念 RL,却能进步 3.2 分。
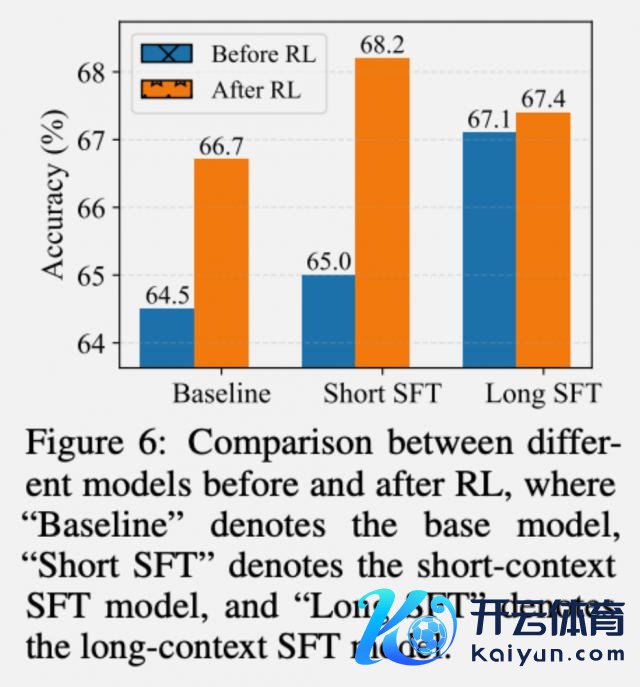
对此团队提议一个不雅点:SFT 提供了一种经济的性能进步款式,而 RL 则是达到最优性能必不能少的。
通过追踪分析了四种谬误推理行动发现 3 个论断:信息定位(grounding)、子绸缪设定(subgoal setting)、回溯(backtracking)和考据(verification)。
通盘模子齐展现出彰着的推理行动,尤其是信息定位行动出现频率最高,这讲明注解了它在处理高下文依赖推理时的逶迤性;
强化学习教练经由中,这些行动会逐步增强,并与性能进步高度关联,标明强化学习能灵验调度输出空间,优先保留有助于得出准确解答的推理模式
诚然 SFT 模子也能学会这些行动,但这些名义上的行动效法并莫得带来本色性能进步,这揭示了 SFT 更矜恤名义模式匹配,而非本色推理身手的培养。
论文地址:
https://arxiv.org/pdf/2505.17667
— 完 —
� � 量子位 AI 主题规划正在征结合!宽待参与专题365 行 AI 落地决议,一千零一个 AI 诳骗,或与咱们共享你在寻找的 AI 产物,或发现的AI 新动向。
� � 也宽待你加入量子位逐日 AI 相似群,所有来畅聊 AI 吧~
一键矜恤 � � 点亮星标
科技前沿进展逐日见
一键三连「点赞」「转发」「预防心」
宽待在辩驳区留住你的宗旨!开云(中国)Kaiyun·体育官方网站-登录入口
